Interesting Linux System Calls
System calls are interfaces exposed by the operating systems to the applications to perform some kind of operations on system resources (files, network, memory, communicate with other processes, etc...), without these interfaces application can't do a whole lot on there own, all they could do is computation. linux has a lot of syscalls (over 500 for x86_64), some are posix (open, read, write ...), and others are linux specific, used to expose some pretty interesting interfaces to help applications get the most performance possible. most of the syscalls covered here are linux specific:
1. clone
clone is like an advanced version of fork, which(fork) basically just copies the process address space, file descriptors, file system state, sighandlers...; clone on the other hand gives more control over those resources, which allows processes to share any resources if they want it.
int clone(unsigned long newsp, unsigned long clone_flags,
int *parent_tidptr,
int *child_tidptr,
unsigned long tls);newsp points to the end of the new stack, the reason we need this, is because if the two processes share the same address space(CLONE_VM), they will share the same stack, which may lead to problems (ex: one process overrides other process data on the stack). clone_flags contains a set of flags each one denote a resource which should be shared between the parent and the child (files, mem, sighands...). parent_tidptr is pointer to a memory area in the parent address space, which will be used to store the child thread id of the child if CLONE_PARENT_SETTID flag is set. child_tidptr is pointer to a memory area in the child address space, which will be used to store the child thread id of the child if CLONE_CHILD_SETTID flag is set. tls is a pointer to a new tls area for the created thread (threads on linux are just processes that share address space and other resources, and belongs to the same thread-group).
2. mmap
mmap is an interface that allows processes to manipulate their address space, e.g the most popular use of it is to map a file to memory and operate on it (without the need to call read/write everytime), just like if the file lives in memory. if a processe requests it the kernel guaranties syncing changes made in memory to disk, which is overall more efficient than manipulate the file using sequences of read/write. or it could be used just to allocate large amount of memory, the allocated memory is in page granularity.
void *mmap(void *addr, size_t length, int prot, int flags,
int fd, off_t offset);addr serve as a hint to the kernel on where to setup the mapping unless MAP_FIXED flag is used, length is the length of the mapping. prot specifies the permissions of the mapping: read, write, execute. flags specifies the nature of the mapping: weather the mapping is just allocated memory MAP_ANONYMOUS; MAP_FIXED to enforce the addr param note this could lead to unmapping of existing maps at that address, or MAP_SHARED: its interpretation depands on the type of the mapping, if it's anonymous mapping it becomes inheritable by child processes, even if the two processes(parent/child) do not share the same address space; but if the mapping is a file it means that changes made in memory should be caried out to disk. MAP_PRIVATE is the opposite of MAP_SHARED. if MAP_ANONYMOUS is not specified, fd points to the file descriptor of the file to be used in the mapping, and offset is where to start the mapping inside the file.
3. futex
futex(2) provides the infrastructures for processes to implement efficient user space locking primitives, though it is possible to do without, but it's inefficient because processes will usually implement locking as a shared flag in memory between processes and atomically acquire it if it's free or busy looping until it's released, wasting cpu cycles for nothing. while the shared lock part is still part of the solution involving futex(2), the busy waiting part is no longer needed, and the kernel will suspand/wake threads on demand.
long futex(uint32_t *uaddr, int futex_op, uint32_t val,
const struct timespec *timeout,
uint32_t *uaddr2, uint32_t val3);uaddr is the address of the lock shared between processes, futex_op specifies the kind of operation to be performed. so after a process checks that the lock is acquired it will call futex(2) with FUTEX_WAIT to tell the kernel to suspend it if the value of the lock in uaddr is still val. note that the kernel is not actively checking uaddr for changes, val is used just to prevent accidently going to sleep while the lock is free; instead it relies on other processes to wake up the waiting processe using FUTEX_WAKE operation which is called by a process after it's done with the lock, this call wakes at most val number of processes.
note that there is other operations supported by futex(2), check the man page for more details.
4. inotify_init, inotify_add_watch, inotify_rm_watch
the inotify family of interfaces allows processes to monitor filesystem events, and get notified whenever something happens to the watched files. to set it up a process need first to initialise the inotify by calling inotify_init which returns a file descriptor, which will be in used in later calls you can think of that fd as a collection of files; to add a file (or a watch) to the collection, call inotify_add_watch and to remove it from the collection call inotify_rm_watch.
/* Structure describing an inotify event. */
struct inotify_event
{
int wd; /* Watch descriptor. */
uint32_t mask; /* Watch mask. */
uint32_t cookie; /* Cookie to synchronize two events. */
uint32_t len; /* Length (including NULs) of name. */
char name[]; /* Name. */
};
int inotify_init(void);
int inotify_add_watch(int fd, const char *pathname,
uint32_t mask);
int inotify_rm_watch(int fd, int wd);inotify_init just initiliases the inotify watch list, and returns the fd to that list, inotify_add_watch adds a file: pathname to the inotify list pointed to by fd, mask is a bit mask of the events we are interested in, it is usually IN_ALL_EVENTS to receive all events, this syscall also returns a fd, that points to the watch we just added, this watch fd could be used to remove it from the inotify list, by calling inotify_rm_watch, where fd is the inotify fd, and wd is the watch fd. now to receive events from our inotiy we use the traditional read(2) syscall which returns a stream of events (of type struct inotify_event) in our buffer, these events have the form of struct inotify_event, which contains the event happened and the file name of the watch.
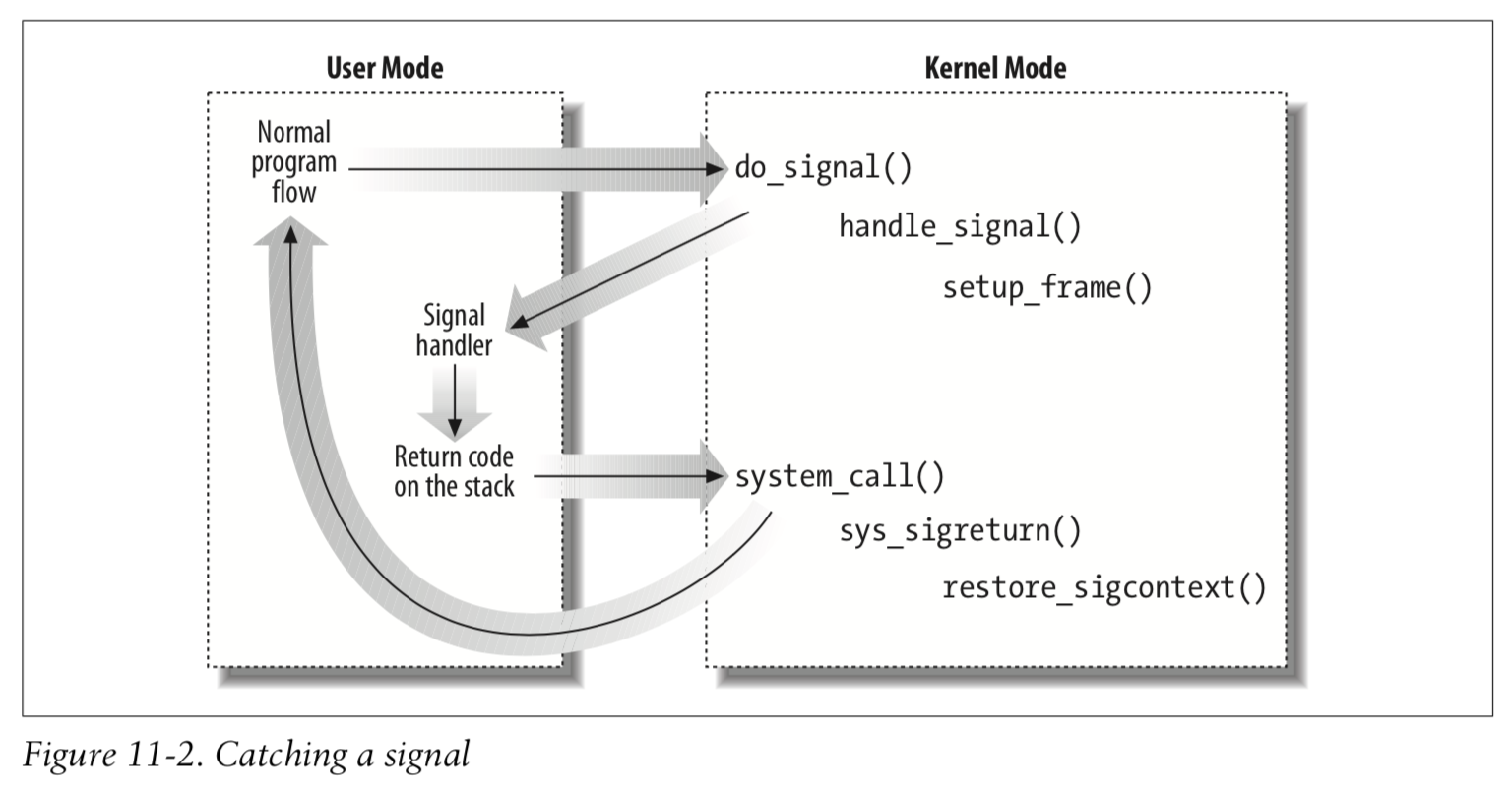
5. sigaction, sigreturn
sigaction(2) is used to install signal handlers. the cool think about is it allows manipulation of the interrupted context. which is semantically similar to hardware interrupts, in a way that allows the handler to inspect that context and even change it.
int sigaction(int signum,
const struct sigaction *restrict act,
struct sigaction *restrict oldact);
/**
* a handler would look like
*/
void handler(int sig, siginfo_t *info, void *context);for example in the handler we could intercept sigfault which would otherwise terminate the process, and establish a valid memory area at the faulting address, allowing the process to continue its operations as if nothing happened:
void handle_sigsegv(int sig, siginfo_t *info,
void *context) {
mmap(info->si_addr, PAGE_SIZE, PROT_READ | PROT_WRITE, MAP_ANONYMOUS | MAP_PRIVATE, -1, 0);
}or maybe dynamic code translation by changing the faulting instrunction to a valid one or skipping it all together:
void handle_sigill(int sig, siginfo_t *info,
ucontext_t *context) {
int *fault_inst = (int *)context->
uc_mcontext.gregs[REG_RIP];
// change it to something valid
// or skip it
context->uc_mcontext.gregs[REG_RIP] += 4;
}we can change any other register we wish.
sigreturn(2) is the hidden part of signal handling it is usually called by libc to inform the kernel that the handling is done, and to restore the interrupted context of the thread.
6. select
this syscall is used to wait for a file descriptor from a list to be ready (either for read or write), though this syscall usage is largely fall in favor of poll(2).
int select(int nfds, fd_set *restrict readfds,
fd_set *restrict writefds,
fd_set *restrict exceptfds,
struct timeval *restrict timeout);7. readv, writev
these syscalls implements scatter/gather io, which basically collects a list of verctors scattered around memory (not in a single buffer) and writes/reads to/from a file. this approach is more efficient in some cases, where users have scathered memory buffers, that needs to be synced with a file. the kernel allows to specify these scattered buffers directly and it will gather them into the specified file.
ssize_t readv(int fd, const struct iovec *iov,
int iovcnt);
ssize_t writev(int fd, const struct iovec *iov,
int iovcnt);8. getxattr, setxattr
xattr are an extension to the traditional unix file attributes (e.g permissions, uid, gid, timestamps ...), these attributes are written in a key/value pairs, and used as a basis to implement other advanced security features such as acl and capabilities. but users can also use these attributes to store aditional metadata about files (e.g checksum cache).
int setxattr(const char *path,
const char *key,
const void *value, size_t size,
int flags);
ssize_t getxattr(const char *path,
const char *key,
void *value, size_t size);path is the filename, key is like the id of the attr, and it is written in the format namespace.attribute normal users only have access to user namespace, attribute part could be any string. value is the value of the attribute, size is the length of the value string. flags used to tune the behaviour of the call.
9. epoll_create, epoll_ctl, epoll_wait
epoll family is like the improved version of select(2). also used to wait for events on files. in its semantics it is similar to inotify. first we create an epoll collection with epoll_create(2) that return a fd to this collection, then we start adding descriptors to it with epoll_ctl(2) specifying which events we are interested in. then we use epoll_wait(2) to wait for an event to happen in one of our registered descriptors.
int epoll_create1(int flags);
int epoll_ctl(int epfd, int op, int fd,
struct epoll_event *event);
int epoll_wait(int epfd, struct epoll_event *events,
int maxevents, int timeout);10. splice
splice(2) is one of many syscalls invented to address a common issue of copying data between file descriptors, traditionally we would use read/write pair to copy data but that is slow, because we are copying data from kernel to user, and then back from user to kernel. it would be better if we could tell the kernel to splice data directly from one fd to another. that's what splice(2) is exactly made for, all the copying is done in kernel without user intervention.
ssize_t splice(int fd_in, off64_t *off_in, int fd_out,
off64_t *off_out, size_t len, unsigned int flags);one of the limitations of splice(2) is that one of the fd's must be a pipe.
11. vmsplice
vmsplice takes the copying problem to the next level. it directly maps user provided buffers into the pipe itself. linux implements pipes by having a buffer(a collection of pages) in the kernel, when the write end of the pipe writes data the kernel copies it from the writing process to the pipe buffer, and when the read end read data, the kernel copies it from the pipe to the buffer of the reading process. vmsplice solve this redundant copying by mapping the buffers provided by the writing user, directly to the pipe.
ssize_t vmsplice(int fd, const struct iovec *iov,
size_t nr_segs, unsigned int flags);note that fd should be a pipe. note also that vmsplice maps buffers only for the write process, for the read end it just copies data. one more note is that the vmsplice requires special handling so that the user do not prematurely override the provided buffers. one excellent blog about pipe performance
12. sendfile
this is another syscall to address the copying problem between kernel and user; except it doesn't have the limitation of working only with pipes; it supports also regular files. it does all the copying in kernel space, it copies count data from in_fd to out_fd.
ssize_t sendfile(int out_fd, int in_fd, off_t *offset,
size_t count);13. memfd_create
this syscall create file entirely in memory, and it is deallocated once it is closed. it is an efficient way for processes that need to work with temperary file.
int memfd_create(const char *name, unsigned int flags);14. mknod
not all files are regular files, in unix there are other types of files, like pipes (named pipes), sockets(unix sockets), device files. to create those use mknod(2) syscall.
int mknod(const char *pathname, mode_t mode, dev_t dev);the file type is encoded in mode. the dev param only used for device files it encodes the device major and minor numbers.
to create fifos we use S_IFIFO mode, named pipes behave exactly like the traditional pipes(unamed) except that this type has a filesystem entry which allows two completly unrelated processes to use it.
we can't create unix sockets with mknod(2); we have to use bind(2) on a unix socket created with socket(2), just like the traditional sockets but only used for local communication between processes (no network access).
15. signalfd
signalfd(2) allows processes to transform a set of signals into file descriptors. usefull for processes that wish to wait for signals through epoll or select(2). the signals need first to be masked out with sigprocmask(2) then when a signal is received it will be turned into an event generated by epoll or select(2).
int signalfd(int fd, const sigset_t *mask, int flags);16. mq_open, mq_timedsend, mq_timedreceive
posix message queue is another ipc mechanism that allows message passing between processes, mq_open create the queue if it doesn't already exists, and mq_timedsend and mq_timedreceive used to send and receive data from the queue.
mqd_t mq_open(const char *name, int oflag);
int mq_timedsend(mqd_t mqdes, const char *msg_ptr,
size_t msg_len, unsigned int msg_prio,
const struct timespec *abs_timeout);
ssize_t mq_timedreceive(mqd_t mqdes,
char *restrict msg_ptr, size_t msg_len,
unsigned int *restrict msg_prio,
const struct timespec *restrict abs_timeout);17. getdents64
directories are different from regular file, so we cannot use the regular file syscalls like read(2) and write(2). in linux to read a directory entries we use getdents64(2).
struct linux_dirent64 {
ino64_t d_ino; /* 64-bit inode number */
off64_t d_off; /* 64-bit offset to next structure */
unsigned short d_reclen; /* Size of this dirent */
unsigned char d_type; /* File type */
char d_name[]; /* Filename (null-terminated) */
};
ssize_t getdents64(int fd, void *dirp, size_t count);it takes a fd to the directory opened with open(2), and a buffer where to receive the entries each entry is of type struct linux_dirent64.
18. statx
each file in unix has 3 time stamps st_atime for last access time, st_ctime for last status change time and st_mtime for the last modification time. the creation time is missing here, and traditional stat(2) do not have that field either. so when linux filesystem start supporting st_btime for birth time, a new interfacec was necessary (statx).
struct statx {
...
struct statx_timestamp stx_atime; /* Last access */
struct statx_timestamp stx_btime; /* Creation */
struct statx_timestamp stx_ctime; /* Last status change */
struct statx_timestamp stx_mtime; /* Last modification */
...
}
int statx(int dirfd, const char *restrict pathname,
int flags, unsigned int mask,
struct statx *restrict statxbuf);19. io_uring_setup, io_uring_register
that's an interesting one, for the longest time async io in linux wasn't trully fully async, epoll is the closest it gets. until now, the way io_uring works is by setting up two queues submission queue and completion queue they are basically two memory maped ring buffers, shared between the kernel and the user, where users submits there io requests(which is any request that could be done with traditional syscalls on a fd, like: read, write, stat, send, recv ...) to submission queues, and frequeuntly checks the completion queue to see if a request is delivered.
int io_uring_setup(u32 entries,
struct io_uring_params *p);
int io_uring_register(unsigned int fd,
unsigned int opcode,
void *arg, unsigned int nr_args);
int io_uring_enter(unsigned int fd,
unsigned int to_submit,
unsigned int min_complete,
unsigned int flags,
sigset_t *sig);to use io_uring applications has to go through the following steps:
- call
io_uring_setupto inform the kernel about the size of the requested ring, then it would describe the layout of our rings in the structurestruct io_uring_params, and return a fd for the uring.
struct io_uring_params *p = malloc(sizeof *p);
/* See io_uring_setup(2) for io_uring_params.flags you can set */
memset(p, 0, sizeof(*p));
ring_fd = io_uring_setup(1, p);- setup the rings. the kernel only tells us about the layout of the rings, it doesn't setup anything, the user is who should create the rings. we do this using mmap:
/**
* works for kernels 5.4 <=
*/
// calculate the size of the sq
int sring_sz = p->sq_off.array +
p->sq_entries * sizeof(unsigned);
// setup sq:
void *sq_ptr = mmap(0, sring_sz, PROT_READ | PROT_WRITE,
MAP_SHARED | MAP_POPULATE,
ring_fd, IORING_OFF_SQ_RING);
// save useful fields for later easy reference
sring_tail = (void *)(sq_ptr +
p->sq_off.tail);
sring_mask = *(unsigned int *)(sq_ptr +
p->sq_off.ring_mask);
sring_array = (void *)(sq_ptr +
p->sq_off.array);
// Map in the submission queue entries array
struct io_uring_sqe *sqe = mmap(0,
p->sq_entries * sizeof(struct io_uring_sqe),
PROT_READ | PROT_WRITE, MAP_SHARED | MAP_POPULATE,
ring_fd, IORING_OFF_SQES);
// calculate the size of cq
int cring_sz = p->cq_off.cqes +
p->cq_entries * sizeof(struct io_uring_cqe);
// setup cq
cq_ptr = mmap(0, cring_sz, PROT_READ | PROT_WRITE,
MAP_SHARED | MAP_POPULATE,
ring_fd, IORING_OFF_CQ_RING);
// save useful fields
cring_head = (void *)(cq_ptr + p->cq_off.head);
cring_tail = (void *)(cq_ptr + p->cq_off.tail);
cring_mask = *(unsigned int *)(cq_ptr +
p->cq_off.ring_mask);
struct io_uring_cqe *cqe = (void *)(cq_ptr +
p->cq_off.cqes);
- submit requests:
/**
* to submit a request we use the tail of sq
* (and the kernel use the head to
* process them)
*/
#define store_release(p, v) \
atomic_store_explicit((_Atomic typeof(*(p)) *)(p),\
(v), memory_order_release)
#define load_aquire(p) \
atomic_load_explicit((_Atomic typeof(*(p)) *)(p), \
memory_order_acquire)
// this should be an atomic op, becaue the tail is shared between kernel and user
int tail = load_aquire(sring_tail);
int index = tail & sring_mask;
struct io_uring_sqe *sqe = &sqes[index];
memset(sqe, 0, sizeof(*sqe));
// let's submit the request: read(fd, add, 1024); but in async way
sqe->opcode = IORING_OP_READ;
sqe->fd = fd; // target fd
sqe->user_data = (unsigned long)0x1; // this is used as an id for the request, the kernel copies it to cq, when the request is done.
sqe->addr = (unsigned long)malloc(1024);
sqe->len = 1024;
sqe->off = 0;
sring_array[index] = index;
tail++;
store_release(sring_tail, tail);
// we inform the kernel that there is a new request
// in the queue (this won't block)
// this could be omitted if the io_uring is created
// with the flag IORING_SETUP_SQPOLL
io_uring_enter(ring_fd, 1, 0, 0, NULL);- get results:
int _head = load_aquire(cring_head);
int _tail = load_aquire(cring_tail);
int head = _head & cring_mask;
int tail = _tail & cring_mask;
// the ring is not empty
if (head != tail) {
// for cq we read from the head,
// and the kernel inserts requests from tail
struct io_uring_cqe *cqe = &cqes[head];
// result of our request, as in the return of read(2)
int res = cqe->res;
_head++;
store_release(cring_head, _head);
}
// if the cq is empty
// we can explicitly block
// and wait for a request to complete using:
// io_uring_enter(ring_fd, 0, 1, 0, NULL);20. seccomp
sometimes we might want to run programs from untrusted sources, which might potentially harm the system, unless we instruct the kernel to restrict operations that could be performed by that program and that is what seccomp(2) (secure computing) is good for.
int seccomp(unsigned int operation, unsigned int flags,
void *args);one usage example is restrict the possible the possible syscalls available for a process:
// this would allow the process the following syscalls:
// read(2), write(2), exit(2), sigreturn(2)
seccomp(SECCOMP_SET_MODE_STRICT, 0, NULL); after the call succeded any attempt to like open(2) a file, or any other operation would kill the process immediatly.
seccomp is kind of similar to openBSD's pledge(2) except it's a more generic interface that could do much more.
21. ptrace
have ever wonder how gdb or strace works, how they could inspect what a process is doing, and alter its behaviour. this is all done through ptrace(2).
long ptrace(enum __ptrace_request request, pid_t pid,
void *addr, void *data);we could create a mini strace using ptrace(2):
pid_t pid;
void start_proc(char **cmd) {
pid = fork();
if (pid > 0) {
// parent
// wait for the child execve(2) call
waitpid(pid, NULL, 0);
ptrace(PTRACE_SETOPTIONS, pid, 0,
PTRACE_O_TRACESYSGOOD);
} else {
// allow tracing by the parent
ptrace(PTRACE_TRACEME);
execvp(*cmd, cmd);
}
}
int main(int argc, char *argv[]) {
if (argc == 1) {
fprintf(stderr, "usage: %s CMD [ARGS...]\n",
argv[0]);
return -1;
}
start_proc(&argv[1]);
int wstatus;
while(1) {
ptrace(PTRACE_SYSCALL, pid, 0, 0);
waitpid(pid, &wstatus, 0);
if (WIFEXITED(wstatus))
exit(WEXITSTATUS(wstatus));
struct ptrace_syscall_info i;
ptrace(PTRACE_GET_SYSCALL_INFO,
pid, sizeof i, &i);
// here we could print the syscall and its args
// syscall: i.entry.nr, args: i.entry.args
}
}23. perf_event_open
performance measurement couldn't be done effictively without hardware/kernel assisstant that's where perf_event_open(2) fits in. the way it works is we inform the kernel about events we are interested in tracking. then starts those counters, after we are done, we stop the counters, and we sample them. the events ranges from cpu performance monitoring counters (e.g cache misses, retired instruction, frontend/backend stalled cycles, cpu cycles ...) to kernel events (e.g. context switches, page faults, cpu migrations ...). perf events are organized as groups, that we can reset,start,stop using ioctl(2).
int perf_event_open(struct perf_event_attr *attr,
pid_t pid, int cpu, int group_fd,
unsigned long flags);thankfully there is a tool called perf that does all the setup, and gives us the counters we are interested in.
24. process_vm_readv, process_vm_writev
every process in linux has it's own private address space (except processes/threads created with CLONE_VM) which no other process has access to. privileged processes can bypass this restriction and directly manipulate other processes address space using process_vm_readv and process_vm_readv.
ssize_t process_vm_readv(pid_t pid,
const struct iovec *local_iov,
unsigned long liovcnt,
const struct iovec *remote_iov,
unsigned long riovcnt,
unsigned long flags);
ssize_t process_vm_writev(pid_t pid,
const struct iovec *local_iov,
unsigned long liovcnt,
const struct iovec *remote_iov,
unsigned long riovcnt,
unsigned long flags);so to read a process address, you would specify it's pid, allocate a local buffer where to receive data and put it in local_iov, and specify the remote address at remote_iov. for writing it's the same thing.
25. sendmsg, recvmsg
usually to have a fd to a resource, you either have to create it, or inherit it from parent process. sendmsg/recvmsg address this short coming, by enabling processes to send and recv fd though unix sockets.
ssize_t sendmsg(int sockfd, const struct msghdr *msg,
int flags);
ssize_t recvmsg(int sockfd, struct msghdr *msg,
int flags);to send a file descriptor you have to fill the struct msghdr and send it to the other process through sockfd:
struct msghdr msg = { 0 };
struct cmsghdr *cmsg;
char placeholder[1];
struct iovec io = {
.iov_base = placeholder,
.iov_len = 1,
};
union {
/* Ancillary data buffer, wrapped in a union
in order to ensure it is suitably aligned */
char buf[CMSG_SPACE(sizeof(int))];
struct cmsghdr __align;
} u;
msg.msg_iov = &io;
msg.msg_iovlen = 1;
msg.msg_control = u.buf;
msg.msg_controllen = sizeof(u.buf);
cmsg = CMSG_FIRSTHDR(&msg);
cmsg->cmsg_level = SOL_SOCKET;
cmsg->cmsg_type = SCM_RIGHTS;
cmsg->cmsg_len = CMSG_LEN(sizeof(int));
// this is the file descriptor to send
*(int *)CMSG_DATA(cmsg) = fd;
sendmsg(sockfd, &msg, 0);the receiving end should be like:
char placeholder[1];
struct iovec io = {
.iov_base = placeholder,
.iov_len = 1,
};
char buf[1024];
struct msghdr msgh = {
.msg_iovlen = 1,
.msg_iov = &io,
.msg_control = buf,
.msg_controllen = sizeof buf,
};
/* Receive auxiliary data in msgh */
recvmsg(sock_fd, &msgh, 0);
struct cmsghdr *cmsg = msgh.msg_control;
// received file descriptor
fd = *(int *)CMSG_DATA(cmsg);
// now we own fd, we can write to it, read it.
// it's an exact copy of fd from the sender
// though it might have different number.26. netlink
the kernel expose many interfaces for the processes to configure it, or to just get information about the running system like proc/sysfs which is a virtual filesystem that provide an interface to communicate with the kernel through the vfs layer. netlink kind of do similar thing it is used for communication between user and kernel, it is a full fledged protocol described in this RFC 3549. one of the goals of netlink is to make it easy to implement newer interfaces in the kernel to communicate with applications; instead of making a new syscall, you would just create a new netlink connection. also netlink is fully async.
27. rseq
implementing a lockless algorithms in multi-threaded apps is hard, because a special care need to be made when accessing shared resources, one of those approaches are per cpu data, because at every single moment there is at most one thread accessing this data. the problem arises when a thread is in the middle of changing the data, and got interrupted and scheduled away, and maybe find itself in a different cpu, this way data is left in inconsistent state. rseq allows apps to atomically run a segment of code, where it could made changes to data. and if it is interrupted by the scheduler or a signal handler, the kernel changes the ip of the thread to an abort handler, where a process can clean up, and restart the restartable sequence over and over until it finished it without interruption. no locking needed.
int rseq(struct rseq * rseq, uint32_t rseq_len,
int flags, uint32_t sig);to use rseq we do the following:
- register rseq:
#define RSEQ_SIG 0x53053053
struct rseq *ret = memalign(sizeof(struct rseq),
sizeof(struct rseq));
memset(ret, 0, sizeof(struct rseq));
ret->cpu_id_start = -1;
// this is updated everytime the thread is scheduled
ret->cpu_id = -1;
rseq(ret, sizeof(struct rseq), 0, RSEQ_SIG);- entering the critical section (restartable seq):
; void operation_rseq(struct rseq * rseq,
; struct percpu *counters) {
; According to the Calling Convention
; the arguments come in registers:
; rseq: %rdi
; counter: %rsi
.p2align 4
.globl operation_rseq
.type operation_rseq, @function
operation_rseq:
.cfi_startproc
; We inform the kernel that
; we are now within a restartable
; sequence by moving a pointer to operation_rseq_cs
; to the kernel-registered rseq object.
; After an abort,
; we also jump to this label (restart_ip)
.restart_ip:
lea operation_rseq_cs(%rip), %rdx
mov %rdx, 8(%rdi)
; The restartable sequence
; Implements: [rseq->cpu_id].counter ++;
; Start of restartable sequence
.start_ip:
mov 4(%rdi), %ecx
sal $6, %rcx
add %rsi, %rcx
incq (%rcx)
; End of restartable sequence
.end_ip:
ret
; The abort trampoline
; Before the abort label,
; the kernel will check if a specific
; signature is present.
; RSEQ_SIG
.long 0x53053053
; On abort, the kernel will jump here
.abort_ip:
jmp .restart_ip
; } End of operation_rseq()
.cfi_endproc
.size operation_rseq, .-operation_rseq
; struct rseq_cs operation_rseq_cs
; -- descriptor for our rseq
.section .data.rel.local,"aw"
.align 32
.type operation_rseq_cs, @object
.size operation_rseq_cs, 32
operation_rseq_cs:
; __u32 version
.long 0
; __u32 flags
.long 0
; __u64 start_ip
.quad .start_ip
; __u64 post_commit_offset
.quad .end_ip - .start_ip
; __u64 abort_ip
.quad .abort_ip
.section .note.GNU-stack,"",@progbitsnote that restartable sequences are written as a series of instructions and a final instruction that commits the change. so that if thread is interrupted in the middle of rseq no harm done, rseq could be safely restarted. for example if we are trying to add an element to a percpu list we would do:
struct list *new;
struct list **head = &lists[cpuid]; // restartable
new->next = *head; // restartable
(*head)->prev = new; // restartable
*head = new; // commit instructionaccording to measurements rseq has much higher performance than lock based algorithm.
28. prctl
processes can control their running state by calling prctl, one of the interesting features it supports is syscall emulation through user space, it was introduced to help wine to catch out bound syscalls made by windows games without going through a library. it works by informing the process that a syscall is made through SIGSYS, then the process can decide what to do with it.
int prctl(int option, unsigned long arg2,
unsigned long arg3,
unsigned long arg4, unsigned long arg5);to setup syscall user dispatching do:
- install
SIGSYShandler
struct sigaction sa = {
.sa_flags = SA_SIGINFO,
.sa_sigaction = usyscall_handler,
};
sigemptyset(&sa.sa_mask);
sigaction(SIGSYS, &sa, NULL);- enable syscall user dispatch
int usyscall_flag = SYSCALL_DISPATCH_FILTER_ALLOW; // this is used to enable and disable syscall dispatch without the need to make a syscall.
prctl(PR_SET_SYSCALL_USER_DISPATCH, PR_SYS_DISPATCH_ON,
0, 0, &usyscall_flag);- emulate syscalls
void usyscall_enable(bool enable) {
usyscall_flag = enable
? SYSCALL_DISPATCH_FILTER_BLOCK
: SYSCALL_DISPATCH_FILTER_ALLOW;
}
void usyscall_signal(int signum, siginfo_t *info,
void *context) {
usyscall_enable(false);
ucontext_t *ctx = (ucontext_t *)context;
greg_t *sc = &ctx->uc_mcontext.gregs[REG_RAX];
uint64_t args[6] = {
ctx->uc_mcontext.gregs[REG_RDI],
ctx->uc_mcontext.gregs[REG_RSI],
ctx->uc_mcontext.gregs[REG_RDX],
ctx->uc_mcontext.gregs[REG_R10],
ctx->uc_mcontext.gregs[REG_R9],
ctx->uc_mcontext.gregs[REG_R8]
};
// e.g if want to disable write(2)
if (*sc == __NR_write) {
errno = ENOSYS;
*sc = -1;
} else {
*sc = syscall(*sc, args[0], args[1],
args[2], args[3], args[4], args[5]);
}
static int register_restorer = false;
if (!register_restorer) {
register_restorer = true;
void *ret =
__builtin_extract_return_addr(
__builtin_return_address (0)
);
// allow libc to call sigreturn(2)
usyscall_init(ret, 20);
};
usyscall_enable(true);
}29. bpf
bpf or rather ebpf (extended berkely packet filter), could be described as runtime sandboxed engine that allows processes to run programs in kernel space, it is like a safe alternative to kernel modules which have full capibility inside the kernel. it is similar to javascript in the browser, you can safely run arbitrary js code in the browser without any harm to the system. the way it works is that applications compiles ebpf programs from higher level languages into a byte code, which is then loaded into the kernel, get verified, and jit compiled into native code. it is a safe way to extend kernel capabilities. it is often used by applications to install event listeners in the kernel and communicate them to user space.
as an example we will create a simple program that counts the number of packets received on a network interface:
- setup the map
a map is sort of the buffer used for communication between ebpf program and userspace
int map_fd = bpf_create_map(BPF_MAP_TYPE_ARRAY,
sizeof(long), sizeof(long), 256);- write ebpf program
we could write ebpf in higher level languages, but for simplicity we will just inline the byte code in the source.
struct bpf_insn prog[] = {
/* r6 = r1 */
BPF_MOV64_REG(BPF_REG_6, BPF_REG_1),
/* r0 = ip->proto */
BPF_LD_ABS(BPF_B, ETH_HLEN +
offsetof(struct iphdr, protocol)),
/* *(u32 *)(fp - 4) = r0 */
BPF_STX_MEM(BPF_W, BPF_REG_10, BPF_REG_0, -4),
/* r2 = fp */
BPF_MOV64_REG(BPF_REG_2, BPF_REG_10),
/* r2 = r2 - 4 */
BPF_ALU64_IMM(BPF_ADD, BPF_REG_2, -4),
/* r1 = map_fd */
BPF_LD_MAP_FD(BPF_REG_1, map_fd),
/* r0 = map_lookup(r1, r2) */
BPF_CALL_FUNC(BPF_FUNC_map_lookup_elem),
/* if (r0 == 0) goto pc+2 */
BPF_JMP_IMM(BPF_JEQ, BPF_REG_0, 0, 2),
/* r1 = 1 */
BPF_MOV64_IMM(BPF_REG_1, 1),
BPF_XADD(BPF_DW, BPF_REG_0, BPF_REG_1, 0, 0),
/* lock *(u64 *) r0 += r1 */
/* r0 = 0 */
BPF_MOV64_IMM(BPF_REG_0, 0),
/* return r0 */
BPF_EXIT_INSN(),
};- load ebpf program
int prog_fd = bpf_prog_load(BPF_PROG_TYPE_SOCKET_FILTER,
prog, sizeof(prog) / sizeof(prog[0]), "GPL");- attach the ebpf to local socket
int sock = open_raw_sock("lo");
setsockopt(sock, SOL_SOCKET, SO_ATTACH_BPF, &prog_fd,
sizeof(prog_fd));- read events
long key, tcp_cnt, udp_cnt;
for (;;) {
key = IPPROTO_TCP;
bpf_lookup_elem(map_fd, &key, &tcp_cnt);
key = IPPROTO_UDP;
bpf_lookup_elem(map_fd, &key, &udp_cnt);
printf("TCP %lld UDP %lld packets\n",
tcp_cnt, udp_cnt);
sleep(1);
}