Git Internals
git is one of the most known software projects out there, and one of the tools that powers opensource, created by linus torvalds, the same person that started linux, his motivation to invent git came mainly from his disappointment from the current scm tools available at the time, mainly cvs and svn. the main design of git is inspired by his extensive experience in designing filesystems. you may think git must be really complicated, to do all of that, but suprisingly it isn't, so let's get into it.
1. Basics
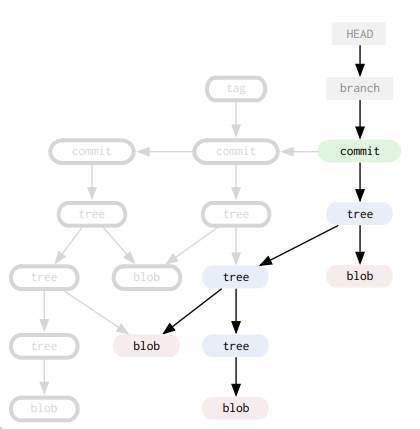
git rely on a concept called content addressable store, means it has no notion of a file, all it sees is the data inside, means if there is two files in a repo with the same content but w/ different paths, git sees only one version of it, because internally it uses sha1sum to represent files. to do its job git consist of things called objects, you can find them on .git/objects/, as we mentioned before those objects are represented internally as sha1sum, one other important thing to remember is that objects are immutable(doesn't change once created) means that whenever you change existing file, git create new file and leave the old one alone, we will see the benefit of that in a moment, there is many types of objects, the most important ones are: blobs, trees, commits. blobs are basically the project's files(text files, images, bins...) and contain the content of the original files. trees on the other hand represents directories and they contains the list of files in those directories, with the original file names, this is how git knows where the files are located, trees can contain other trees as well. finally commits are the central unit of git, it represents a project snapshot in any particular moment of time, how commits works is by having a reference, to the root tree of the project, wich inturn have references to other blobs(file), and trees(dir) as well, to represent the entire project recursively. to demonstrate how that looks in real world, we will use a tool called git-cat-file it comes by default with git, and it allows us to inspect objects, and see what they really are. now it's demo time so find existing repo, or create one with few commits, then to see available objects by runing:
$ ls .git/objects
04 0a 12 2d 37 4c 5a 64 6b 6e 95 96 9d bb c5 c9 cb d3 dc dd de df e4 e6 f7 fait returns a list of a bunch of directories, with the first two letters of the hash of the objects inside, we will inspect different objects from different types, to see how each one looks.
2. Objects
blob:
note that you can't read the objects directly from .git dir, because they are zlib compressed, this where git-cat-file comes to play. to verify the type of an object use '-t' option:
$ git cat-file -t 87fd173868664c251b409bb1ad544511636a6b07
bloband it should output the object type wether it is: blob, tree, or commit.
to see the content of the object run:
$ git cat-file -p 87fd173868664c251b409bb1ad544511636a6b07
file contentso basically blobs just stores the file content.
tree:
$ git cat-file -p 0447f0a71054812d6abf72e4d1a1364d73ab6ba8
100644 blob faec8727e6c2a5ef763ddd1a3a660457c686a44c .gitignore
040000 tree 997d755483fc456f555773186b0efc4495d5a78a scripts
040000 tree 2d9bf8be7ded4651456fe40656ccf57785574560 src
040000 tree 5acfcff9b69fc8b68dc8c7918fca56e84be0a5b4 utilsas you can see trees links blobs, and trees together, just like directories in the traditional filesystem, tree is what gives blobs a meaning, without trees, blobs are just content storage, with no way to know the actual file they represent, so trees came to fill in that gap.
commit:
$ git cat-file -p 0a4c4379d4a4fa43444e271289f34f6cd65a89e2
tree 0447f0a71054812d6abf72e4d1a1364d73ab6ba8
parent c531604dfa7813dafabae913749e1ebb7f43d726
author Nour-eddine Taleb <[email protected]> 1622495529 +0100
committer Nour-eddine Taleb <[email protected]> 1622495529 +0100
commit message is herecommit is what glue everything together, it has ref to the project root tree, and link to the parent commit, and other metadata, it represent the state of the project(snapshot) when it was taken, this is why objects are immutable once they are created, because they might be referenced by other commits, so basically when you did a change to existing file git create new object for it, instead of altering the existing one, but it keeps referencing the old files if you didn't touch them.
3. References
you can think of refs as pointers, wich include heads(branches), tags, remotes, you can find them in .git/refs they are basically text file so you can read them directly:
heads (branches)
$ cat .git/refs/heads/master
0a4c4379d4a4fa43444e271289f34f6cd65a89e2as you can see branches(heads), are just pointer to an object, as you might guessed this object is a commit, let's verify it:
$ git cat-file -t 0a4c4379d4a4fa43444e271289f34f6cd65a89e2
commitremotes
remotes are links to other external repositories, they work the same as heads:
$ cat .git/refs/remotes/origin/master
0a4c4379d4a4fa43444e271289f34f6cd65a89e2tags
tags are the same as branches, but they are immutable once created and points to a commit, it can't change anymore
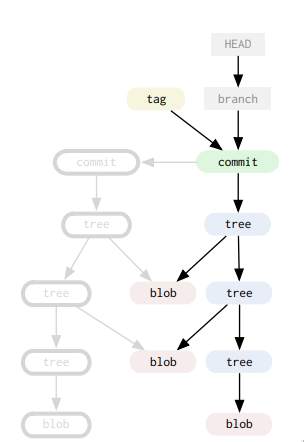
HEAD
you can find it in .git/HEAD, it basically points to the current branch
$ cat .git/HEAD
ref: refs/heads/masterResources:
https://raw.githubusercontent.com/pluralsight/git-internals-pdf/master/drafts/peepcode-git.pdf