DIY Docker
docker and others(lxc, podman...) are progams that allows the creation of lightweight virtualization, as opposed to real virtualization (type 1) it's software based emulated by the kernel, through a feature called namespaces in linux. it makes the process think it's in a separate machine with different settings (mount points, time, user id, ipc, pid, network interfaces, cpu count/memory amount, hostname), and the process can manipulate it's environment however it likes (with proper capabilities of course) like a real root.
1. Inro to Namespaces
a namespace is a wrapper of a set of system resources, each namespace type controls different type of resources. in linux the types of namespaces are:
a. User
this namespace isolates user/group id, so that a process can have different user/group id inside and outside the namespace.
b. UTS
uts namespace controls the hostname.
c. Time
time namespace controls the monotonic clock, and the boot time
d. Mount
mount namespace controls mount points so that processes could have different view of the filesystem tree.
e. IPC
controls POSIX and systemv ipc.
f. CGroup
controls the set of resources available to the processes within the namespace like memory and cpu.
g. Network
have control over network interfaces, ports.
h. PID
creates a new pid tree for the processes within the namespace.
2. Build Root Image
before creating the namespaces we first need a root filesystem where our processes will live and will be their root. we will use buildroot to build a simple image:
git clone --depth 1 git://git.buildroot.net/buildroot buildroot(cd buildroot; make defconfig; make -j`nproc`)3. Setup Namespaces & Exec Init
none of the subsequent operations requires root privileges.
to setup the new namespaces in c:
unshare(CLONE_NEWTIME
|CLONE_NEWNS
|CLONE_NEWCGROUP
|CLONE_NEWUTS
|CLONE_NEWIPC
|CLONE_NEWUSER
|CLONE_NEWPID
|CLONE_NEWNET);
int ret = fork();
// exit parent
if (ret != 0)
exit(0);
// init boot time
int fd = open("/proc/self/timens_offsets", O_WRONLY);
// replace 12685 with time found in /proc/uptime
write(fd, "7 -12685 0", 10);
close(fd);
// map user id 1000 to 0 (root)
fd = open("/proc/self/uid_map", O_WRONLY);
write(fd, "0 1000 1", 8);
close(fd);
// map group id 1000 to 0 (root)
fd = open("/proc/self/gid_map", O_WRONLY);
write(fd, "0 1000 1", 8);
close(fd);
// chdir to the buildroot filesystem
chroot("buildroot/output/target/");
chdir("/");
mount("proc", "/proc", "proc",
MS_NOSUID|MS_NODEV|MS_NOEXEC, NULL);
execve("/bin/sh", ["/bin/sh"], envp);
the most important part is the unshare(2) call wich informs the kernel to create new namespaces for the current process. this may seem like a lot of work but there is a tool that will effectively do the same it's a wrapper arround unshare(2):
unshare --fork --user --mount --uts --ipc \
--net --pid --cgroup --time \
--map-root-user \
--root=buildroot/output/target/ \
--boottime=-`cat /proc/uptime \
|cut -d' ' -f1 \
|cut -d'.' -f1` \
--mount-proc /bin/shthe results should look like this:
the process is bound to the given resources and won't be able to escape the jail.
4. Networking
it would be nice if our "container" could connect to the outside world, so let's setup some basic networking:
a. virtual interface
as mentioned above having a separate net namespace means having different network devices, ips ..., so we need to create a virtual interface that will link our container with the host machine, which will act as a router:
- host:
doas ip link add veth0 type veth peer name veth1the host will have veth0 and the container will have veth1. now we need to move veth1 to the container, but before we do that we have to register our net namespace in ip tool:
doas ip netns attach diy-container <pid of a process within the container>move veth1 to the container:
doas ip link set veth1 netns diy-containerfrom here there is two possible solutions the first is to to bridge container interface with the hardware interface, the second one is to use network address translation, and route packets through the host.
Solution #1: BRIDGE
this is more easier to configure and the recommended approach for its transparency:
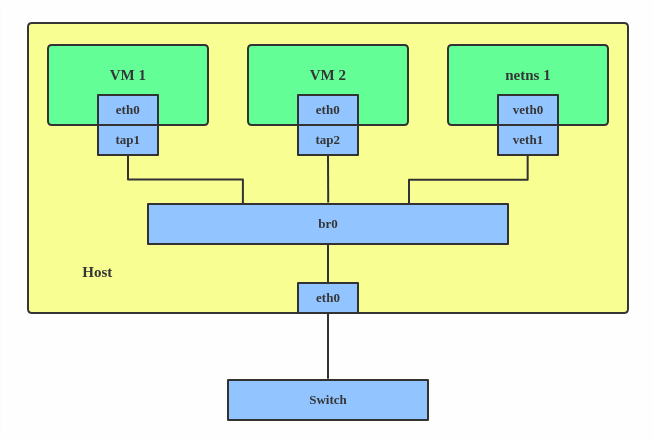
b. setup a bridge
we will create a bridge that will link the physical interface with the virtual interface of the container. first take note of the current network status:
- host:
# save the ip address:
# replace enp0s1 with the interface connected to internet
ip addr show enp0s1
# save the gateway:
ip route show dev enp0s1For example, this is the relevant info:
IP address attached to enp0s1: 10.2.3.4/24 Default gateway: 10.2.3.1
now let's create the bridge and configure it.
ip link add br0 type bridge
ip link set dev br0 up
ip address add 10.2.3.4/24 dev br0
ip route add default via 10.2.3.1 dev br0link the veth with physical interface:
ip link set enp0s1 master br0
ip address del 10.2.3.4/24 dev enp0s1
ip link set veth0 master br0now the container has physical access to the network just like the host; it just need to be configured:
- container:
# replace 10.2.3.5 with an available ip
ip address add 10.2.3.5/24 dev veth1
ip route add default via 10.2.3.1 dev veth1now we have full access to the physical network:
ping 8.8.8.8
PING 8.8.8.8 (8.8.8.8): 56 data bytes
64 bytes from 8.8.8.8: seq=0 ttl=118 time=201.878 ms
64 bytes from 8.8.8.8: seq=1 ttl=118 time=214.774 ms
64 bytes from 8.8.8.8: seq=2 ttl=118 time=112.869 msSolution #2: NAT
b. connect the host and the container
now if we check the list of devices inside the container we should get:
- container:
ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
4: veth1@if5: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue state DOWN qlen 1000
link/ether da:2b:31:d0:b0:39 brd ff:ff:ff:ff:ff:ffsetup the address:
ip addr add 10.0.0.2/24 dev veth1
ip link set veth1 upwe should do the same in the host:
- host:
doas ip addr add 10.0.0.1/24 dev veth0
doas ip link set veth0 upnow we have a connection, we can ping both ways:
ping 10.0.0.2
PING 10.0.0.2 (10.0.0.2) 56(84) bytes of data.
64 bytes from 10.0.0.2: icmp_seq=1 ttl=64 time=0.053 ms
64 bytes from 10.0.0.2: icmp_seq=2 ttl=64 time=0.057 ms- container:
ping 10.0.0.1
PING 10.0.0.1 (10.0.0.1) 56(84) bytes of data.
64 bytes from 10.0.0.1: icmp_seq=1 ttl=64 time=0.053 ms
64 bytes from 10.0.0.1: icmp_seq=2 ttl=64 time=0.057 msc. route container packets
finally we have to allow container packet to go through the network if needed:
- host:
allow ip forwarding:
echo 1 | doas tee /proc/sys/net/ipv4/ip_forwardadd NAT:
# replace enp0s1 with net interface connected to the network
doas iptables -t nat -A POSTROUTING -o enp0s1 -j MASQUERADE- container:
finally set the default gateway of the container:
ip route add default via 10.0.0.1 dev veth1now we can reach the network from the container:
ping 8.8.8.8
PING 8.8.8.8 (8.8.8.8): 56 data bytes
64 bytes from 8.8.8.8: seq=0 ttl=118 time=201.878 ms
64 bytes from 8.8.8.8: seq=1 ttl=118 time=214.774 ms
64 bytes from 8.8.8.8: seq=2 ttl=118 time=112.869 ms